We consider a simple general-purpose technique for reducing latency, redundancy: initiate multiple copies of latency-sensitive operations, and take the first copy to complete. Redundancy has been explored in some past systems, but these tend to be the exception, not the rule. In general, redundancy is avoided because of a fear of the overhead it adds.
We study the latency-overhead tradeoff from redundancy both empirically in real-world applications, and analytically using queueing and economic models. We characterize when redundancy is and isn't beneficial overall, and identify a large class of systems where it does achieve a substantial improvement.
Our results show that redundancy should be used much more commonly than it currently is.
- Low latency via redundancy
Ashish Vulimiri, Brighten Godfrey, Radhika Mittal, Justine Sherry, Sylvia Ratnasamy, Scott Shenker
CoNEXT 2013 - More is less: Reducing latency via redundancy
Ashish Vulimiri, Oliver Michel, Brighten Godfrey, Scott Shenker
HotNets 2012 - A cost-benefit analysis of low latency via added utilization
Ashish Vulimiri, Brighten Godfrey, Scott Shenker
arxiv preprint
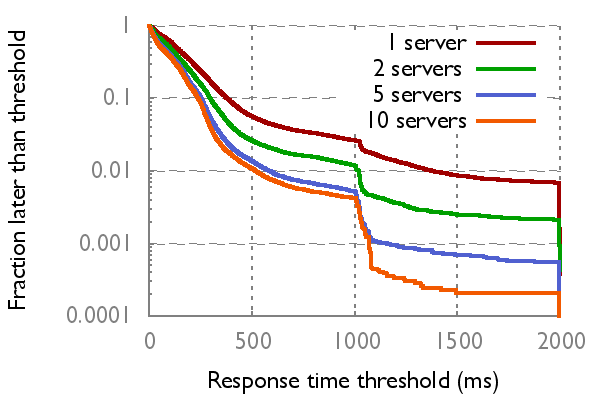
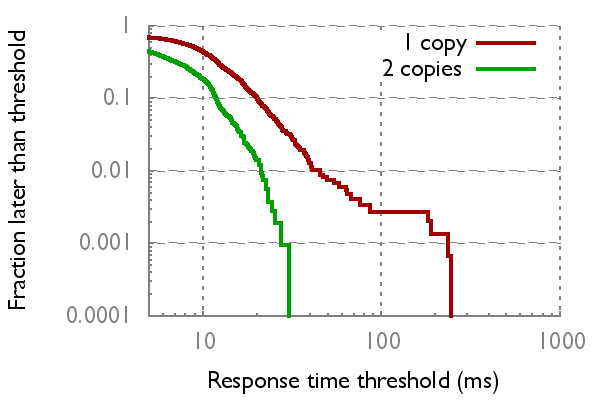
| DNS | Key-value store (read requests) | |
|
|
|
| Up to 62% better mean/tail DNS request latency. DNS redundancy can yield up to 15% better browser page load times, see [arxiv preprint] for details. |
2x better mean latency, 8x better tail on Amazon EC2 |